Hands-on DDD and Event Sourcing [4/6]: Implementing Event Sourcing
In the previous post, I talked about Domain events and Event Sourcing. Now let’s look at persisting, projecting, and reading events using MartenDB.
- Part 1 - EcommerceDDD overview
- Part 2 - Strategic and Tactical Design
- Part 3 - Domain events and Event Sourcing
- Part 4 - Implementing Event Sourcing
- Part 5 - Wrapping up infrastructure (Docker, API gateway, IdentityServer, Kafka)
- EcommerceDDD++: Streamlining API Client Generation with Kiota and Koalesce
What is MartenDB?
Marten is a .NET library that allows developers to use the Postgresql database as both a document database and a fully-featured event store – with the document features serving as the out-of-the-box mechanism for projected “read side” views of your events.
As their website describes, it was built to replace RavenDb inside a very large web application that was suffering stability and performance issues.
While studying event sourcing, I looked for an out-of-the-box implementation so I could easily revamp this project from a relational database to an event-sourced one. The library is aligned with .NET Core Support Lifecycle to determine platform compatibility, and they seem to be constantly improving it. You can check their project on GitHub and their nice documentation at MartenDb.io. I followed their documentation to use what I needed for this project.
Postgres as document database
PostgreSQL is a powerful, open source object-relational database system with over 30 years of active development that has earned it a strong reputation for reliability, feature robustness, and performance.
You’ve seen it before: we need to persist serialized events in an event store, and the perfect place for it is a document-oriented database rather than a relational one. Using Postgres is a viable option, especially considering its support for JSON. It was a perfect match for MartenDB.
Writing and Reading events
To ease writing and reading events with Marten, I opted for a pragmatic abstraction using the IEventStoreRepository, which you can find in the EcommerceDDD.Core project, implemented in EcommerceDDD.Core.Infrastructure/Marten with MartenRepository.
I don’t advocate generic repositories when designing aggregate roots, but this was a straightforward solution for persisting domain events. Still, there’s a constraint that ensures it works only for an aggregate root, which complies with the base class that contains a queue of uncommitted IDomainEvents, ready to be stored.
Last but not least, the repository implementation uses an abstraction called IDocumentStore, allowing us to use different flavors of what they call a session. Notice how it resembles a Unit of Work / DBContext when using Entity Framework.
AppendEventsAsync (TA aggregate)
At first, this method opens a store session, and the underlying code does the following procedure:
- Gets all uncommitted events from the aggregate.
- Calculates the aggregate’s next version for return.
- Clear all uncommitted events from the aggregate.
- Appends the uncommitted events.
- Calls SaveChangesAsync to commit the transaction
At the end, you can expect the database to contain a snapshot of the system state.
FetchStreamAsync(Guid id, int? version)
The method brings the aggregate from the event stream by Id. There’s an optional version argument in case you need to load a specific version.
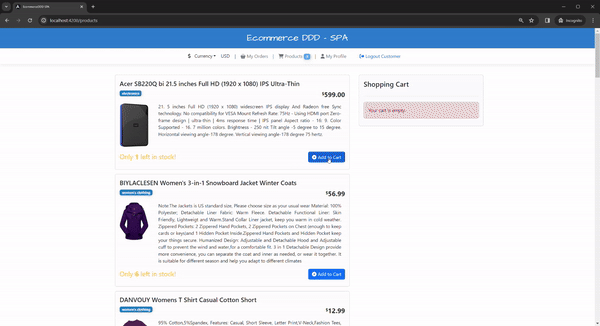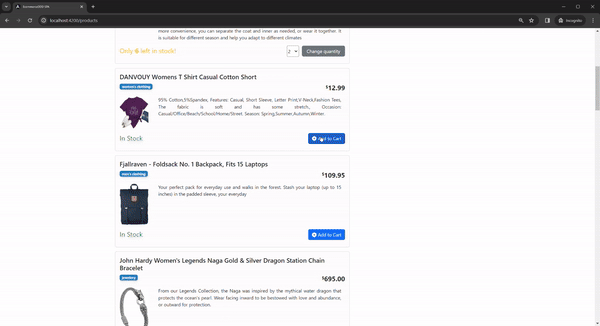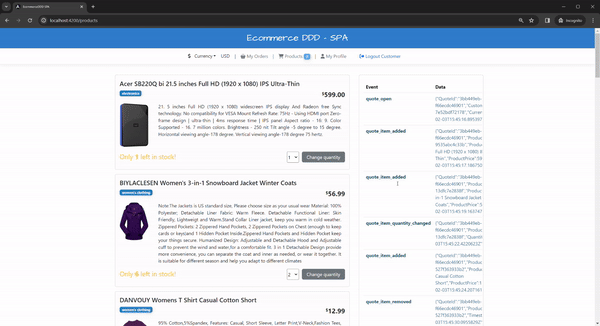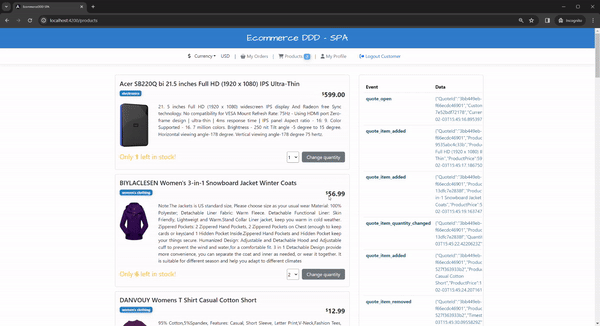
One interesting thing you can do is add breakpoints to all Apply methods of any aggregate, such as Quote, and then perform operations like adding or removing products or changing quantities. All these behaviors are commands that generate events and persist in the event stream. Lastly, when calling the FetchStreamAsync afterward for this aggregate again, you can track the Apply for each event sequence and check it rehydrating the aggregate.
The Event Store
Assuming you ran the app, it should have created a couple of databases for each microservice. I’m using pgAdmin as a GUI for managing Postgresdb, and it’s already set as a docker container for you in this project:
Still about Quotes for an order, let’s see how the data is handled under the hood. I mentioned earlier that every database performs read and write operations separately using different “tables”. When querying the quotes_write event store, we can see the sequence of every event added in chronological order:
1
2
SELECT * FROM quotes_write.mt_events
ORDER BY seq_id ASC

Notice the columns stream_id, which carries the Aggregate id itself, the version, the data with the serialized event, the type name, and the dotnet_type describing the namespace and class name of the event. Cool, eh?
Projections
You’ve seen that we need to load the entire sequence of events to rehydrate the aggregate and get the current state. The example above shows at least six, but there’s no limit. Imagine a system in production handling thousands or hundreds of thousands of events per aggregate per user, and every time you query a particular object, you have to traverse all this path to recreate it and reach the latest state, which is practically impossible to scale.
To solve this problem, you need to project only the latest states of the aggregate somewhere, more specifically, to the read database or table. That’s another feature I found handy with MartenDB: inline projections. It’s easy to set the projection of an event immediately as it’s stored. When the UI needs the API to query information, it reads it directly from the data projected in the read DB. The configuration is as simple as this:
Notice that the first projection QuoteDetailsProjection inherits from SingleStreamAggregation for aggregating events by stream using pattern matching, where QuoteDetails is the actually projected object into the database table mt_doc_quotedetails.
1
2
SELECT * FROM quotes_read.mt_doc_quotedetails
ORDER BY id ASC

The second projection, QuoteEventHistoryTransform is meant to be simpler, inheriting from the EventProjection base class to project each one of the possible events this aggregate contains, but transforming it into an object of the IEventHistory interface I created to standardize the history of all aggregates and to ease displaying it through the stored-events-viewer Angular component we will check in the last chapter of the series.
One of the beauties of using Event Sourcing is that we can shape the projected data as we need it, in many different forms for different visualizations, and place it in different places, without changing the original, immutable source of truth: the event store. Even if you destroy the read-only store containing the projections completely, you can reproject it to the exact last state over again, like rolling frames of a movie.
Write-side performance: projections solve the read problem, but rehydrating a very long event stream on the write side can also become costly. For those cases, MartenDB supports aggregate snapshots — a persisted point-in-time state of the aggregate, so that rehydration starts from the snapshot rather than replaying every event from the beginning.
Final thoughts
In this post, you saw how MartenDB bridges the gap between Postgres and a fully functional event store, allowing you to write and read domain events without giving up on a familiar relational database infrastructure.
You walked through the IEventStoreRepository abstraction and its Marten-backed implementation, which handles appending uncommitted events and rehydrating aggregates from their event streams. You also saw how inline projections for live read-model updates and EventProjection for custom event transformations that keeps the read side current without any extra plumbing.
The key takeaway is that Event Sourcing is not just about storing events — it’s about structuring your system around the idea that the event history is the truth, and every other representation is derived from it.
In the next post of the series, I’ll cover the infrastructure layer: Docker, API gateway, IdentityServer, and Kafka — the pieces that tie the whole system together. See you there!
Links worth checking
- Aggregates, Events, Repositories with Marten
- EventSourcing.NetCore
- CQRS pattern
- Event Streaming is not Event Sourcing! by Oskar Dudycz
- Optimistic concurrency for pessimistic times
- Domain events
- Ubiquitous language
- Bounded context