In the previous post, I delved a bit more into bounded contexts and some of the building blocks of the implementation. Now, let’s extend the implementation to domain events.
- Part 1 - EcommerceDDD overview
- Part 2 - Strategic and Tactical Design
- Part 3 - Domain events and Event Sourcing
- Part 4 - Implementing Event Sourcing with MartenDB
- Part 5 - Wrapping up infrastructure (Docker, API gateway, IdentityServer, Kafka)
- EcommerceDDD++: Streamlining API Client Generation with Kiota and Koalesce
Domain Events
Before we jump into Event Sourcing, let’s clarify a common confusion: there are many types of events in software architecture, but not all events are domain events, and domain events don’t necessarily imply Event Sourcing.
A domain event represents an immutable fact that has already occurred in the domain — the result of a business behavior. Ideally, your aggregates should expose explicit behaviors (rather than being anemic ), and from those behaviors, domain events are born. Once again, ubiquitous language plays a key role in how these events are named and understood.
Domain events are always context-bound; their meaning holds only within the bounded context where they originated.
When naming events, consider their context with high-value semantics, and use a combination of the [Noun][PastTenseVerb] (e.g. CustomerRegistered, OrderShipped).
What about Integration events?
Although they look similar, Domain and Integration events serve different purposes and operate at different scopes.
- Domain Events: Trigger reactions within the same bounded context. They usually use in-memory synchronous dispatch (e.g., calling handlers inside the same process).
- Integration Events: Trigger reactions across different bounded contexts or external systems, and are typically handled asynchronously using a messaging infrastructure. Since they fan out across service boundaries, they require decoupling and tolerate non-deterministic response times.
To stream integration events, you’ll usually use a message broker or event bus. There are many options available. In this project, I’m using Kafka for educational purposes, but I’ve also had great experiences with RabbitMQ. We’ll cover the implementation when tackling the infrastructure.
Event Sourcing
In short, Event Sourcing is an architectural pattern in which state changes are represented as a sequence of events, and these events serve as the source of truth.
Logging events is not a new concept in software, but Greg Young shaped the technique into the form we call Event Sourcing nowadays.
Events are chronologically persisted in what’s called an Event Store. For this to work consistently, the store has to be immutable, which means events are always appended but never changed or deleted.
Furthermore, Event Sourcing allows us to shift from the conventional approach, where retrieved data is used only for the domain object’s last state, to reading the domain object’s event history and rehydrating it to its latest state. Also, writing and reading events are completely separate operations that can scale independently, which is why Event Sourcing pairs naturally with CQRS — they are independent patterns, but complement each other very well.
There’s no rule of thumb for the technology you use to implement Event Sourcing. Some good players in the market, such as Event Store do the job very efficiently, but since I’m using Postgres as a document database, MartenDB was the natural choice.
With Event Sourcing:
- Each state transition in an aggregate is captured as a domain event.
- Events are persisted chronologically in an event store, not as overwrites of the current state.
- The system rebuilds aggregate state by
rehydratingit from its stream of past events.
Why use Event Sourcing?
This approach offers powerful advantages:
- You no longer face object-relational impedance mismatch — you store data as it was intended: event-based and serialized.
- You get a natural audit trail — the complete event history reveals how and why the current state exists.
- You get independent scalability between reads and writes, which leads us to CQRS.
Embedded complexity
Keep in mind that the learning curve can be quite steep with all the details, depending on your implementation. Consider things like handling concurrency, where multiple users can edit the same record simultaneously, and ensuring they occur in the proper order. There’s a very nice article where the author covers this subject excellently, and I don’t dare try to explain it better. He also maintains this awesome repo that inspired me with many ideas to convert this study project into something event-sourced.
That said, Event Sourcing comes with complexity. You’ll need to deal with:
- Concurrency and optimistic locking.
- Schema evolution (when event structures change over time).
- Event versioning
- Performance tuning of long event streams.
CQRS: Command Query Responsibility Segregation
CQRS is an architectural pattern that is often mentioned alongside Event Sourcing, and for good reason. They pair perfectly.
Commandsexpress user intents and actions. Commands will be the triggers to change the state of our aggregate and emit events on the write side.Queriesretrieve materialized views of the current state. They are handled in the read model.
This separation allows your write model to focus purely on domain logic and emitting events, while your read model is optimized for performance and user experience. In the next post, I’ll explore Projections, the mechanism for building and updating read models.
Hands-on
Let’s walk through a simple example using the Customer aggregate root. After the domain invariants are validated, the domain object is built, and the AppendEvent and the Apply methods are called in sequence:
1
2
AppendEvent(@event);
Apply(@event);
- AppendEvent is defined in the AggregateRoot base class, and it adds the event to the uncommitted events Queue of IDomainEvent.
- Apply method mutates the aggregate state based on the @event argument it overrides. Each applied event mutates a corresponding part of the aggregate.
Important: in-process domain event handlers should only be dispatched after the aggregate is successfully persisted. Triggering side effects before a confirmed commit risks inconsistency — if persistence fails, the effects have already happened. This is precisely the problem the Outbox Pattern (covered in Part 5) addresses on the integration event side.
Take this example from the UpdateCustomerInformation command. Instead of directly modifying customer fields, it emits a CustomerUpdated event, which is then handled through Apply:
SAGA - Coordinating distributed workflows
Integration events enable cross-service communication, but coordinating a multi-step business workflow — where each step depends on the previous one succeeding — requires a dedicated pattern: SAGA. It manages data consistency across distributed services without a global transaction.
The successful ordering flow is handled in the OrderSaga.cs:
flowchart TB
subgraph SUCCESS[" "]
direction LR
OP([OrderPlaced]):::event --> PO[ProcessOrder]:::cmd --> OPD([OrderProcessed]):::event --> RP[RequestPayment]:::cmd
RP -.-> PF([PaymentFinalized]):::event
PF --> RS[RequestShipment]:::cmd --> SF([ShipmentFinalized]):::event
end
classDef event fill:#f5a623,stroke:#c47f0e,color:#1a1a1a,font-weight:bold
classDef cmd fill:#7db4de,stroke:#4d8cb8,color:#1a1a1a
However, there are failing cases you have to be prepared to handle and compensate for the flow, somehow. For example, what if you purchase more products than are available in stock? Or what if you exceed the credit limit and can’t complete the payment? I implemented compensation events in each microservice and placed the handling for these cases into the OrderSagaCompensation.cs to cancel the order:
flowchart TB
subgraph COMP[" "]
direction LR
PFail([PaymentFailed]):::event --> CA1[CancelOrder]:::cmd --> OC1([OrderCanceled]):::event
CRL([CustomerReachedCreditLimit]):::event --> CA2[CancelOrder]:::cmd --> OC2([OrderCanceled]):::event
SFail([ShipmentFailed]):::event --> CA3[CancelOrder]:::cmd --> OC3([OrderCanceled]):::event
OOS([ProductWasOutOfStock]):::event --> CA4[CancelOrder]:::cmd --> OC4([OrderCanceled]):::event
OCE([OrderCanceled]):::event --> RCP[RequestCancelPayment]:::cmd --> PC([PaymentCanceled]):::event
end
classDef event fill:#f5a623,stroke:#c47f0e,color:#1a1a1a,font-weight:bold
classDef cmd fill:#7db4de,stroke:#4d8cb8,color:#1a1a1a
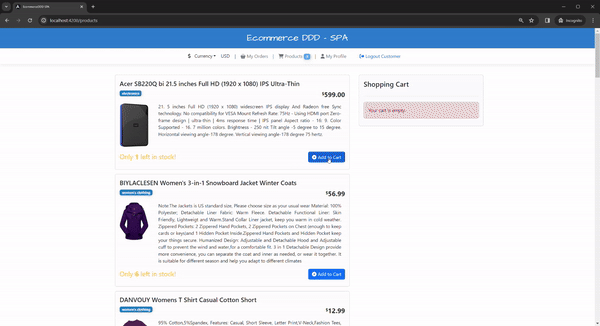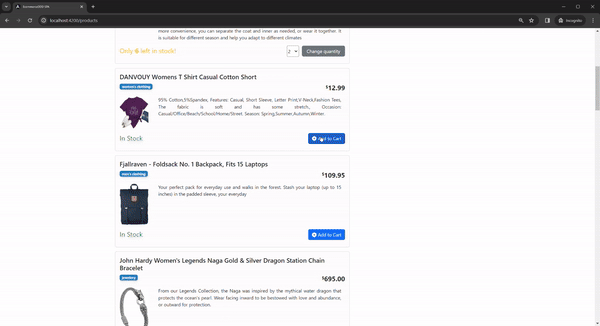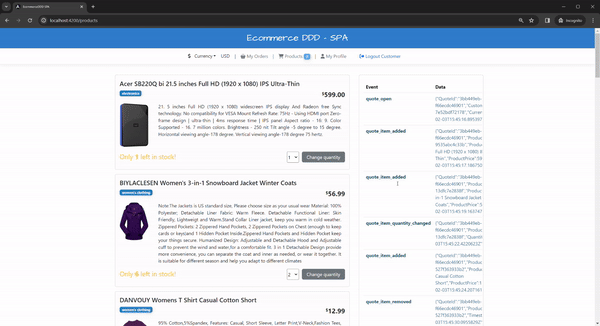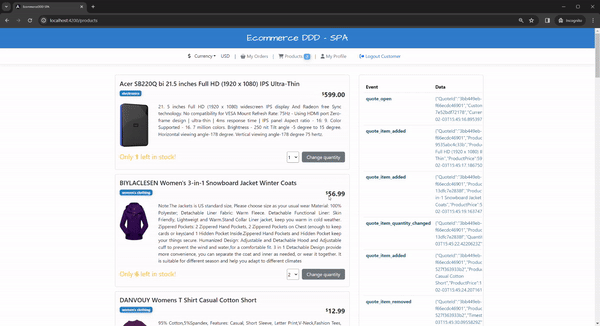
For testing the compensation flows, try to either spend more than your credit limit or purchase more products than available in stock:
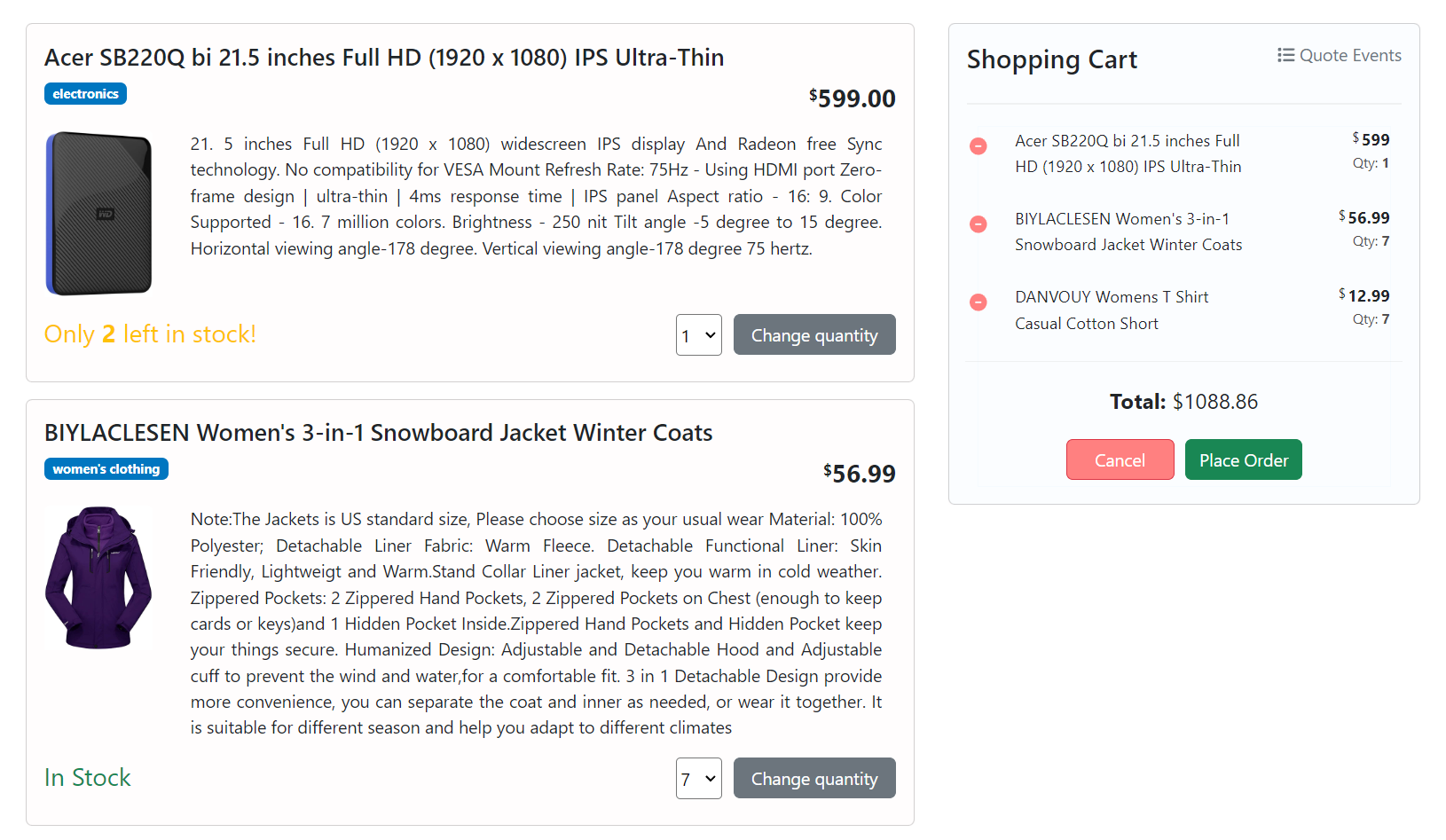
That will result in a canceled order:

A quick check in the events will show exactly the reason:
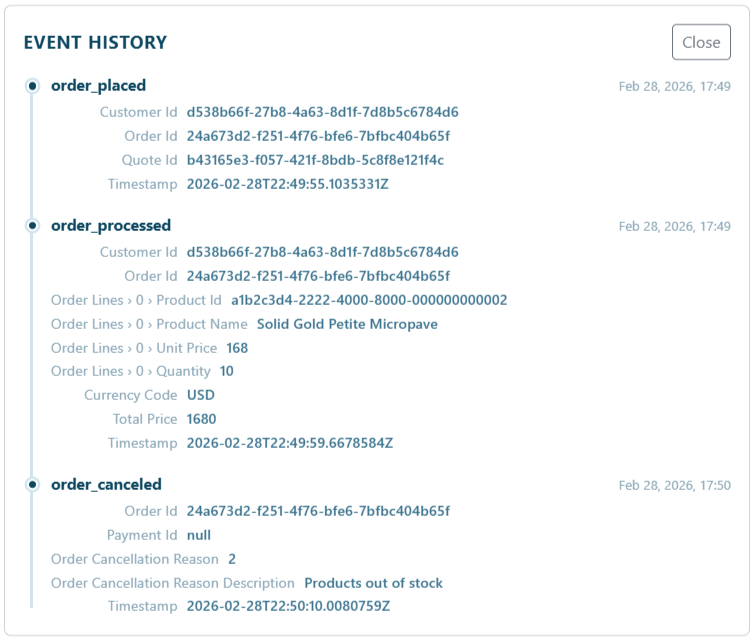
Each compensation event results in a cancellation command, including a reason and a reference. In real-world scenarios, you’d likely implement a more nuanced approach (e.g., backorders), but this implementation demonstrates the concept well.
It’s worth noting that both OrderSaga and OrderSagaCompensation apply a ThrowIfFailed pattern: any Result.Fail returned by the command bus is converted into an InvalidOperationException. This is what ties saga correctness to Kafka’s offset commit — if a saga step fails, the exception bubbles up to the consumer, no commit happens, and the message is retried automatically. Compensation itself benefits from the same mechanism: if CancelOrder fails because, say, the order service is momentarily unreachable, the compensation event will also be retried.
⚠️ The Kafka broker and the infrastructure that give the SAGA its at-least-once delivery guarantee are covered in Part 5.
Final thoughts
Everything we’ve seen so far establishes the foundations: how domain events represent state changes within a bounded context, how integration events coordinate reactions across services, and how the SAGA pattern orchestrates multi-step distributed workflows. What we haven’t done yet is persist any of it — all the state lives in memory.
In the next post, I’ll walk you through persisting domain events to the write database and projecting them to a read-optimized database using MartenDB projections.
Links worth checking
- Aggregates, Events, Repositories with Marten
- CQRS pattern
- Event Streaming is not Event Sourcing! by Oskar Dudycz
- Optimistic concurrency for pessimistic times
- Domain events
- Ubiquitous language
- Bounded context